Di artikel observability sebelumnya, kita sudah membahas OpenTelemetry untuk mengumpulkan sinyal, Jaeger untuk distributed tracing, Falco untuk runtime security events, dan Loki bersama Grafana untuk centralized logging. Semua sinyal itu membantu engineer memahami request, perilaku runtime, dan output aplikasi. Metrics menambahkan lapisan penting berikutnya: metrics membantu kita melihat apakah sistem sehat, seberapa parah sebuah masalah, dan apakah ada tindakan yang perlu diambil.
Metrics bukan pengganti logs, traces, atau security events. Metrics biasanya menjadi cara paling cepat untuk menyadari bahwa ada sesuatu yang berubah. Setelah itu, logs dan traces sering membantu menjelaskan kenapa perubahan itu terjadi, sementara security events membantu menemukan perilaku mencurigakan yang belum tentu terlihat seperti kegagalan aplikasi biasa.
Artikel ini membahas Prometheus dan Grafana dari sudut pandang platform engineering yang praktis: bagaimana metrics dikumpulkan, bagaimana dashboard membantu tim membaca kesehatan service, dan bagaimana alerts mengubah gejala menjadi tindakan operasional.
Recap: Di Mana Metrics Masuk dalam Observability
Observability lebih mudah dipakai ketika setiap sinyal punya peran yang jelas.
Metrics adalah pengukuran numerik dari waktu ke waktu. Metrics menjawab pertanyaan seperti:
- Apakah service tersedia?
- Apakah latency sedang naik?
- Apakah error meningkat?
- Apakah database connection pool sudah jenuh?
- Apakah queue backlog sedang bertambah?
- Apakah cluster mulai kehabisan CPU, memory, atau disk?
Traces menunjukkan jalur request antar-service. Logs menunjukkan detail spesifik dari aplikasi. Security events menunjukkan aktivitas runtime yang mencurigakan. Metrics membantu engineer tahu harus mulai melihat dari mana.
Metrics
menjawab: apa yang berubah, seberapa besar, seberapa parah
contoh: 5xx rate naik dari 0.2% menjadi 8%
Traces
menjawab: request berjalan lewat mana dan menghabiskan waktu di mana
contoh: checkout-api -> payment-api -> payment-provider
Logs
menjawab: apa yang dilaporkan aplikasi
contoh: provider timeout saat memproses payment method
Security Events
menjawab: perilaku runtime mencurigakan apa yang terjadi
contoh: shell dijalankan di dalam container productionWorkflow incident yang baik sering dimulai dari metrics. Dashboard atau alert menunjukkan bahwa latency naik, error rate melonjak, atau sebuah dependency terlihat tidak sehat. Dari situ, engineer berpindah ke traces dan logs untuk memahami jalur request dan konteks aplikasi.
Masalah yang Diselesaikan oleh Metrics
Sistem production menghasilkan terlalu banyak aktivitas untuk diperiksa manual oleh manusia. Di Kubernetes, sebuah backend service bisa berjalan di banyak pod, node, namespace, dan cluster. Request bisa melewati ingress, service mesh proxy, application container, queue, cache, database, dan third-party API.
Tanpa metrics, engineer sering terjebak dengan pertanyaan yang terlalu kabur:
- Apakah service benar-benar down, atau hanya satu customer yang terkena path bermasalah?
- Apakah masalah ini baru muncul, atau sudah memburuk perlahan?
- Apakah latency tinggi untuk semua request, atau hanya endpoint tertentu?
- Apakah error rate cukup tinggi untuk membangunkan on-call?
- Apakah queue sedang mengejar backlog, atau makin tertinggal?
- Apakah database overload, atau aplikasi membocorkan connections?
Metrics mengubah pertanyaan itu menjadi time-series data. Alih-alih menebak apakah checkout-api terasa lambat, tim bisa melihat percentile request duration. Alih-alih menebak apakah failure tersebar luas, tim bisa membandingkan error rate berdasarkan service, route, status code, namespace, atau deployment.
Tradeoff-nya, metrics perlu didesain dengan hati-hati. Metric yang terlalu umum bisa menyembunyikan masalah. Metric dengan terlalu banyak labels bisa membebani monitoring system. Metric yang tidak dipahami siapa pun hanya menjadi dekorasi dashboard.
Metrics yang baik harus membantu pengambilan keputusan operasional.
Apa Itu Prometheus?
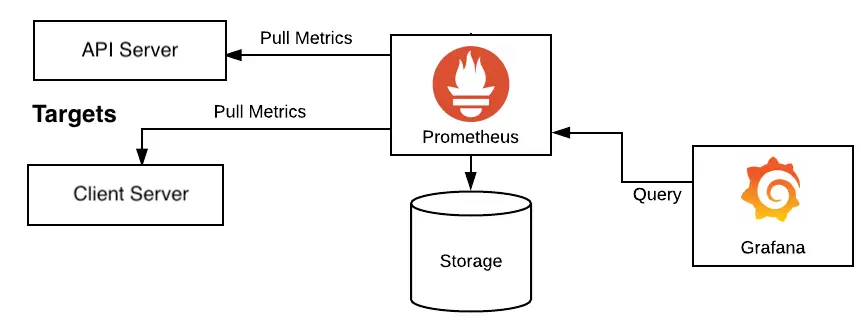
Prometheus adalah sistem untuk metrics collection, storage, dan query yang dibangun di atas time-series data. Prometheus mengumpulkan sampel numerik dari waktu ke waktu, menyimpannya bersama labels, lalu memungkinkan engineer melakukan query menggunakan PromQL.
Dalam setup yang umum, aplikasi dan exporters mengekspos metrics lewat HTTP, biasanya di endpoint /metrics. Prometheus secara berkala melakukan scrape ke endpoint tersebut dan menyimpan sampelnya di time-series database.
Application / Exporter
mengekspos /metrics
|
v
Prometheus
scrape metrics secara berkala
|
v
Time-Series Database
|
v
PromQL Queries
dashboard, alerts, investigasiModel ini berbeda dari pendekatan push-first ketika setiap aplikasi mengirim metrics langsung ke endpoint pusat. Prometheus biasanya menarik metrics dari scrape targets yang sudah diketahui. Pull model ini membuat service discovery, target health, dan scrape configuration menjadi bagian penting dari platform.
Sebagai contoh, sebuah backend API bisa mengekspos metrics seperti:
http_requests_total{service="checkout-api",method="POST",route="/checkout",status="500"} 42
http_request_duration_seconds_bucket{service="checkout-api",route="/checkout",le="0.5"} 1840
db_connections_in_use{service="checkout-api",database="orders"} 38
queue_messages_ready{queue="payment-events"} 1200Prometheus menyimpan sampel ini dari waktu ke waktu. Setelah datanya tersedia, tim bisa menjawab pertanyaan operasional seperti:
- Berapa 5xx rate untuk
checkout-apidalam 5 menit terakhir? - Apakah p95 latency naik setelah deployment terbaru?
- Namespace mana yang mengalami CPU throttling paling tinggi?
- Apakah worker queue bertambah lebih cepat daripada kemampuan consumer mengurasnya?
- Apakah database connections sudah mendekati limit konfigurasi?
Apa Itu Grafana?
Grafana adalah layer untuk dashboard, visualisasi, dan eksplorasi yang sering dipakai bersama Prometheus. Prometheus menyimpan dan melakukan query metrics. Grafana membantu manusia membaca dan memeriksanya.
Dashboard Grafana bisa menampilkan service health, request rate, latency percentile, error ratio, resource usage, saturation, queue depth, dan perilaku dependency. Grafana Explore memberi ruang untuk menjalankan ad hoc query ketika dashboard belum cukup.
Grafana berguna karena raw metrics sulit dibaca saat incident sedang panas. Dashboard yang baik bisa menjawab beberapa pertanyaan awal dengan cepat:
- Apakah service menerima traffic?
- Apakah error rate berubah?
- Apakah latency berubah?
- Apakah masalah terbatas pada satu route, pod, cluster, atau dependency?
- Apakah resource saturation terjadi sebelum atau sesudah gejala muncul?
Grafana juga membantu menghubungkan sinyal. Sebuah metric panel bisa mengarahkan engineer ke logs terkait di Loki atau traces di Jaeger maupun tracing backend lain. Ini penting karena metrics biasanya menunjukkan gejala, bukan seluruh penyebab.
Bagaimana Prometheus dan Grafana Terhubung
Prometheus dan Grafana sering dibahas bersamaan, tetapi tanggung jawabnya berbeda.
Prometheus mengumpulkan, menyimpan, dan melakukan query metrics. Grafana menampilkan dan mengeksplorasi metrics tersebut. Alerting bisa dikonfigurasi melalui Prometheus alerting rules, Grafana alerting, atau kombinasi keduanya tergantung platform. Dalam banyak sistem yang berorientasi Prometheus, Prometheus mengevaluasi alert rules dan mengirim alert yang firing ke Alertmanager.
Backend Service
mengekspos application metrics
|
v
Prometheus
scrape, menyimpan, mengevaluasi rules
|
+------> Alertmanager
| routing notifications
|
v
Grafana
dashboard, panel, eksplorasiBagi platform team, poin pentingnya adalah kepemilikan operating model:
- Aplikasi harus mengekspos metrics yang berguna.
- Komponen platform harus menyediakan metrics cluster dan workload.
- Prometheus harus melakukan scrape ke target yang reliable dan mengevaluasi rules penting.
- Grafana harus membuat data mudah dipahami.
- Alertmanager harus mengarahkan actionable alerts ke tempat yang tepat.
Stack ini bekerja paling baik ketika mencerminkan cara service benar-benar gagal.
Konsep Inti
Metrics
Metric adalah pengukuran bernama. Biasanya metric merepresentasikan sesuatu yang bisa dihitung, diukur, atau diamati dari waktu ke waktu.
Jenis metric yang umum mencakup counters, gauges, histograms, dan summaries. Secara praktis:
- Counters naik terus dari waktu ke waktu, misalnya total requests atau total errors.
- Gauges bisa naik atau turun, misalnya memory usage atau queue depth.
- Histograms mengelompokkan observasi ke dalam buckets, misalnya request durations.
- Summaries juga mendeskripsikan distribusi, tetapi histograms sering lebih mudah diagregasi lintas instance di Prometheus.
Untuk service health, tim sering mulai dari metode RED:
- Rate: berapa banyak request yang terjadi?
- Errors: berapa banyak request yang gagal?
- Duration: berapa lama request berjalan?
Untuk infrastructure dan dependencies, tim sering melihat saturation:
- CPU usage dan throttling
- Memory usage
- Disk usage dan IO
- Database connection pool usage
- Queue backlog
- Thread pool atau worker pool usage
Pengukuran ini membantu engineer membedakan antara gejala dan masalah kapasitas.
Labels
Labels adalah pasangan key-value yang ditempelkan pada metrics. Labels membuat metrics bisa di-query berdasarkan dimensi seperti service, route, status code, namespace, pod, cluster, atau environment.
Contoh:
http_requests_total{
service="checkout-api",
namespace="payments",
method="POST",
route="/checkout",
status="500"
}Labels sangat kuat karena memungkinkan engineer membedah metric yang sama dari banyak sudut. Request counter yang sama bisa menjawab pertanyaan berdasarkan service, route, status code, namespace, atau cluster.
Labels juga membawa risiko. Setiap kombinasi unik dari metric name dan labels membentuk satu time series. High-cardinality labels bisa menghasilkan terlalu banyak time series dan membuat Prometheus mahal atau tidak stabil untuk dioperasikan.
Hindari labels yang nilainya tidak terbatas:
user_idemailrequest_idtrace_id- raw URL path dengan ID, seperti
/orders/938475 - error message dengan teks dinamis
Lebih baik gunakan labels yang bounded:
servicenamespaceroutemethodstatusclusterenvironment
Cardinality bukan kekhawatiran teoritis. Satu label yang buruk bisa melipatgandakan storage, memory usage, query cost, dan waktu evaluasi alert. Untuk platform engineer, label governance adalah bagian dari mengoperasikan Prometheus dengan aman.
Scrape Targets
Scrape target adalah HTTP endpoint yang dibaca Prometheus secara terjadwal. Aplikasi, exporters, dan komponen platform mengekspos metrics. Prometheus menemukan target tersebut lalu melakukan scrape.
Endpoint yang umum dipakai adalah /metrics.
Prometheus scrape interval: 15s
Target: checkout-api:8080/metrics
-> mengambil sampel metric terbaru
-> parse Prometheus text format
-> menyimpan sampel dengan labels dan timestamp
-> menandai target up atau downScrape model menciptakan sinyal operasional yang berguna: Prometheus bisa memberi tahu apakah sebuah target bisa di-scrape. Jika up{job="checkout-api"} menjadi 0, Prometheus tidak bisa melakukan scrape ke target tersebut. Itu tidak selalu berarti service down, tetapi berarti visibilitas monitoring sedang rusak atau endpoint tidak dapat dijangkau.
Di Kubernetes, Prometheus biasanya menemukan target melalui service discovery, annotations, ServiceMonitor resources, PodMonitor resources, atau model konfigurasi lain yang spesifik ke operator.
Exporters
Tidak semua sistem mengekspos Prometheus metrics secara native. Exporters menjembatani gap itu. Exporter mengambil metrics dari sebuah sistem dan mengeksposnya dalam format Prometheus.
Contoh umum:
node-exporteruntuk metrics node Linux seperti CPU, memory, filesystem, dan network.kube-state-metricsuntuk state object Kubernetes seperti deployments, pods, replicas, dan node conditions.- Database exporters untuk PostgreSQL, MySQL, Redis, dan data store lain.
- Message broker exporters untuk sistem seperti RabbitMQ atau Kafka.
Di Kubernetes, exporters membantu platform team melihat kesehatan platform, bukan hanya aplikasi.
Kubernetes Cluster
|
+-- Application Pods
| mengekspos /metrics
|
+-- node-exporter
| mengekspos node metrics
|
+-- kube-state-metrics
| mengekspos Kubernetes object state
|
+-- database / queue exporters
mengekspos dependency metrics
Prometheus
scrape semua target yang dikonfigurasi
Grafana
menampilkan kesehatan service, workload, node, dan dependencyDi titik ini metrics menjadi sangat berguna untuk platform engineering. Jika latency checkout-api naik, platform team bisa memeriksa apakah masalahnya sejajar dengan pod restarts, CPU throttling, node pressure, database saturation, atau queue backlog.
PromQL
PromQL adalah query language untuk Prometheus. PromQL dipakai untuk memilih, memfilter, mengagregasi, dan menghitung time-series data.
Kita tidak perlu menjadi ahli PromQL di hari pertama. Titik awal yang praktis adalah belajar cara:
- Memilih metric berdasarkan nama dan labels.
- Menghitung rate dari counters.
- Mengagregasi berdasarkan dimensi yang berguna.
- Membandingkan perilaku terbaru dengan threshold.
- Membangun latency percentile dari histograms.
Contoh ide query:
5xx rate by service:
rate(http_requests_total{status=~"5.."}[5m])
Request rate by route:
sum by (route) (rate(http_requests_total{service="checkout-api"}[5m]))
Database connections in use:
db_connections_in_use{service="checkout-api"}Nama metric yang tepat bergantung pada aplikasi dan instrumentation library. Kebiasaan yang penting adalah menanyakan pertanyaan terkecil yang masih berguna. Saat incident, query yang jelas lebih berguna daripada query pintar yang tidak bisa dijelaskan siapa pun.
Alerts
Alerts mengubah kondisi metric menjadi notifikasi. Dalam setup yang berorientasi Prometheus, Prometheus mengevaluasi alerting rules. Ketika sebuah rule firing, Prometheus mengirim alert ke Alertmanager. Alertmanager menangani grouping, routing, silencing, inhibition, dan pengiriman notification.
Prometheus Rule
expression: error rate terlalu tinggi selama 10 menit
|
v
Prometheus
mengevaluasi rule sesuai jadwal
|
v
Alertmanager
grouping, routing, silencing, deduplication
|
v
Notification Channel
on-call, Slack, email, incident toolAlerts yang baik harus actionable. Alert sebaiknya menunjukkan masalah yang berdampak ke user, risiko yang jelas, atau kondisi yang membutuhkan respons manusia tepat waktu.
Alerts yang lemah biasanya firing dari gejala noisy tanpa konteks:
- CPU di atas 80% untuk satu pod selama satu menit.
- Satu response 500.
- Satu pod restart di namespace mana pun.
- Queue depth lebih besar dari nol.
Alerts yang lebih baik mempertimbangkan severity, duration, dan impact:
checkout-api5xx ratio di atas 5% selama 10 menit.- p95 latency di atas service objective selama 15 menit.
- Queue backlog bertambah selama 20 menit ketika consumers terlihat sehat.
- Database connection pool di atas 90% selama 10 menit dengan request latency yang ikut naik.
- Prometheus tidak bisa scrape critical targets selama beberapa interval.
Tujuannya bukan alert untuk setiap angka yang tidak normal. Tujuannya adalah memberi tahu manusia ketika tindakan memang dibutuhkan.
Contoh Praktis
Bayangkan sebuah platform Kubernetes menjalankan backend service bernama checkout-api. Service ini menerima checkout request, memanggil payment-api, menulis order ke PostgreSQL, dan mem-publish message ke queue untuk fulfillment asynchronous.
Tim sudah menginstrumentasi service dengan HTTP metrics, database pool metrics, dan queue metrics. Prometheus melakukan scrape ke application pods dan exporters. Grafana punya dashboard untuk domain checkout.
Suatu pagi, sebuah alert firing:
Alert:
checkout-api high 5xx ratio
Condition:
5xx responses berada di atas 5% selama 10 menit
Pertanyaan pertama:
Apakah ini isolated, makin parah, atau sudah recovery?Platform engineer membuka Grafana dan memeriksa service dashboard.
Metric Alert
checkout-api 5xx ratio tinggi
|
v
Grafana Service Dashboard
request rate, error rate, latency
|
v
Breakdown by route and status
/checkout mengalami kenaikan 502 responses
|
v
Dependency Panels
latency payment-api naik
database pool terlihat normal
queue backlog stabil
|
v
Logs and Traces
periksa request path yang gagal dan konteks errorMetrics menunjukkan bahwa hanya POST /checkout yang terdampak. Request rate normal, tetapi p95 latency naik sebelum 5xx spike. Database connections masih di bawah saturation. Queue backlog tidak bertambah. Dependency panel untuk payment-api menunjukkan latency naik dan timeout errors.
Pada titik ini, metrics sudah mempersempit investigasi. Metrics belum sepenuhnya menjelaskan penyebabnya. Engineer kemudian memeriksa traces untuk checkout request yang lambat dan logs untuk checkout-api serta payment-api pada window waktu yang terdampak.
Trace mungkin menunjukkan:
checkout-api
POST /checkout
|
v
payment-api
POST /payments/charge
|
v
external payment provider
timeout setelah 3 detikLogs mungkin menunjukkan bahwa endpoint provider mengalami timeout untuk satu region atau satu payment method tertentu. Metrics menunjukkan gejala dan mempersempit blast radius. Traces dan logs menjelaskan jalur request serta detail operasionalnya.
Pola yang sama berlaku untuk masalah lain:
- Latency increase bisa mengarah ke CPU throttling, dependency yang lambat, atau database contention.
- Queue backlog bisa menunjukkan workers tidak mampu mengejar incoming work.
- Database connection saturation bisa menjelaskan request latency dan timeouts yang naik.
- Scrape target yang down bisa menunjukkan monitoring gap atau service yang tidak bisa dijangkau.
Dalam workflow observability yang sehat, metrics adalah entry point, bukan jawaban akhir.
Metrics yang Baik vs Metrics yang Buruk
Metrics yang baik terasa membosankan dalam arti yang bagus. Stabil, mudah dipahami, bounded, dan terhubung dengan pertanyaan operasional.
Metrics yang buruk menciptakan noise, cost, atau kebingungan. Di dashboard mungkin terlihat berguna, tetapi saat incident gagal membantu karena tidak ada yang tahu tindakan apa yang harus diambil.
Metric yang Baik
name: http_requests_total
labels: service, route, method, status
use: menghitung request rate dan error ratio
action: mengidentifikasi service dan endpoint terdampak
Metric yang Buruk
name: request_failed_for_user
labels: user_id, email, request_id, error_message
use: terlalu banyak unique series
action: tidak jelas dan mahal untuk di-queryMetrics yang baik biasanya punya ciri seperti:
- Menjawab pertanyaan operasional yang nyata.
- Punya unit yang jelas.
- Labels-nya bounded dan disengaja.
- Bisa diagregasi lintas pod atau instance.
- Mendukung alerting atau investigasi.
- Tetap berguna setelah deployment dan scaling event.
Metrics yang buruk biasanya punya masalah seperti:
- Memakai high-cardinality labels.
- Menduplikasi logs sebagai metrics.
- Terlalu spesifik untuk satu code path.
- Tidak terdokumentasi atau tidak dipahami.
- Memicu alerts tanpa respons yang jelas.
- Mengukur detail internal yang tidak berdampak ke user atau operasi.
Metrics sebaiknya didesain sebagai bagian dari service contract. Backend API perlu mengekspos informasi yang cukup agar operator memahami traffic, errors, latency, saturation, dan dependency utama. Namun tidak semua variable perlu diubah menjadi time series.
Hal yang Perlu Diwaspadai
Risiko pertama adalah high cardinality. Prometheus bisa menangani banyak data, tetapi bukan sihir. Labels seperti user_id, request_id, raw path, atau dynamic error text bisa menciptakan jumlah series yang sangat besar. Ini meningkatkan memory pressure, storage usage, query latency, dan operational risk.
Risiko kedua adalah alert fatigue. Jika setiap deviasi kecil menghasilkan notification, engineer akan belajar mengabaikan alerts. Alerts sebaiknya merepresentasikan kondisi yang membutuhkan tindakan, bukan setiap gerakan grafik yang menarik.
Risiko ketiga adalah dashboard overload. Dashboard dengan 60 panel mungkin terlihat mengesankan, tetapi bisa memperlambat incident response. Dashboard yang baik harus membuat pertanyaan awal mudah dijawab:
- Apakah traffic normal?
- Apakah errors naik?
- Apakah latency naik?
- Apakah saturation terlihat?
- Apakah masalah terisolasi berdasarkan route, pod, namespace, cluster, atau dependency?
Risiko keempat adalah mencampuradukkan gejala infrastructure dengan user impact. CPU tinggi mungkin masih bisa diterima jika latency dan error rate sehat. Pod restart mungkin tidak penting jika deployment tetap available. Sebaliknya, kenaikan resource yang terlihat kecil bisa penting jika berkorelasi dengan p95 latency atau customer-facing errors yang naik.
Risiko kelima adalah memperlakukan metrics sebagai seluruh cerita observability. Metrics sangat baik untuk mendeteksi pola dan severity. Metrics lebih lemah dalam menjelaskan detail perilaku aplikasi. Ketika metric alert firing, engineer biasanya tetap membutuhkan logs, traces, deployment history, dan kadang security events.
Metric
memberi tahu: checkout-api 5xx ratio tinggi
|
v
Dashboard
memberi tahu: /checkout dan payment dependency terlihat terdampak
|
v
Trace
memberi tahu: request menunggu panggilan payment-api
|
v
Log
memberi tahu: provider timeout pada operasi charge
|
v
Action
rollback, fail over, adjust timeout, scale worker, atau escalate dependencyPlatform yang matang membuat alur ini mudah. Engineer harus bisa bergerak dari alert ke dashboard, dari dashboard ke logs atau traces, lalu dari sana ke mitigasi yang konkret.
Penutup
Prometheus dan Grafana memberi platform team cara praktis untuk memahami kesehatan service. Prometheus mengumpulkan dan melakukan query time-series metrics. Grafana mengubah metrics itu menjadi dashboard dan workflow eksplorasi. Alertmanager membantu routing kondisi penting ke orang yang perlu merespons.
Nilainya bukan pada memiliki lebih banyak grafik. Nilainya ada pada kemampuan mengetahui apakah sistem sehat, seberapa parah masalahnya, dan apakah tindakan diperlukan.
Metrics sering menjadi sinyal pertama saat incident. Metrics menunjukkan bentuk, timing, dan blast radius sebuah masalah. Setelah itu, logs, traces, dan security events membantu menjelaskan penyebab dan konteksnya. Jika dipakai bersama, sinyal-sinyal ini membuat operasi backend dan infrastructure lebih sedikit bergantung pada tebakan dan lebih berbasis evidence.
Bagi platform engineering team, setup metrics yang baik harus membuat incident berikutnya lebih mudah dipahami: apa yang berubah, siapa yang terdampak, ke mana harus melihat berikutnya, dan tindakan apa yang layak diambil.