Di artikel observability sebelumnya, kita mulai dari gambaran besar observability, lalu masuk ke OpenTelemetry untuk pengumpulan signal, Jaeger untuk distributed tracing, dan Falco untuk runtime security events. Tool-tool itu membantu kita memahami bagaimana request bergerak antar service dan bagaimana sistem berperilaku saat berjalan.
Logs tetap menjadi bagian penting dari cerita itu.
Metrics memberi tahu bahwa ada sesuatu yang berubah. Traces menunjukkan di mana sebuah request menghabiskan waktu. Security events memberi sinyal saat ada perilaku runtime yang mencurigakan. Logs sering menjawab pertanyaan praktis berikutnya: apa yang sebenarnya dikatakan aplikasi saat kejadian itu berlangsung?
Artikel ini membahas stack centralized logging yang praktis: Loki sebagai log aggregation backend, Grafana sebagai layer eksplorasi dan visualisasi, dan Logstash sebagai layer pemrosesan opsional ketika environment logging membutuhkan parsing, enrichment, filtering, atau routing sebelum logs sampai ke tujuan akhir.
Recap: Kenapa Logs Tetap Penting
Kadang logs dianggap tidak terlalu penting lagi setelah tim punya metrics dan traces. Di praktiknya, logs tetap berguna karena membawa konteks spesifik dari aplikasi yang belum tentu ada di signal lain.
Misalnya, trace bisa menunjukkan bahwa request ke payment API gagal di span charge-card. Metric bisa menunjukkan lonjakan response 5xx. Log line bisa menjelaskan bahwa payment provider menolak request karena idempotency key tidak valid, konfigurasi merchant hilang, atau terjadi timeout ke dependency eksternal.
Setiap signal menjawab jenis pertanyaan yang berbeda:
Metrics
-> Apa yang berubah?
-> Seberapa sering?
-> Seberapa parah?
Traces
-> Request berjalan ke mana saja?
-> Service atau operation mana yang lambat?
-> Jalur request seperti apa?
Logs
-> Apa yang dilaporkan aplikasi?
-> Cabang logic mana yang berjalan?
-> Konteks detail apa yang terekam?
Security Events
-> Perilaku runtime mencurigakan apa yang terjadi?
-> Process, file, container, atau rule mana yang terlibat?Observability yang baik bukan berarti memilih satu signal lalu mengabaikan yang lain. Tujuannya adalah memakai signal yang tepat pada momen yang tepat, lalu berpindah antar signal dengan cepat.
Logs sangat berguna saat debugging business logic, kegagalan integrasi, input yang tidak terduga, regresi deployment, dan incident operasional ketika aplikasi mengetahui lebih banyak detail dibanding infrastruktur.
Masalah yang Diselesaikan oleh Centralized Logging
Untuk aplikasi kecil yang berjalan di satu server, membaca logs dari file lokal mungkin cukup. Di Kubernetes atau platform cloud-native, pendekatan itu cepat menjadi sulit.
Pods dibuat dan dihancurkan. Containers berpindah antar node. Backend API bisa berjalan dengan banyak replica. Jobs bisa hidup hanya beberapa menit. Satu request yang gagal bisa melibatkan ingress controller, API service, worker, cache, database client, dan integrasi pihak ketiga.
Tanpa centralized logging, engineer sering terjebak pada pertanyaan operasional yang melelahkan:
- Pod mana yang menangani request gagal?
- Apakah pod itu masih ada saat investigasi dimulai?
- Apakah logs tersebar di banyak node?
- Bisakah logs dicari berdasarkan service, namespace, environment, atau deployment?
- Bisakah logs dikorelasikan dengan spike metric atau trace yang sudah ditemukan?
- Berapa lama logs disimpan?
Centralized logging memberi tim platform satu tempat untuk mengumpulkan, mencari, dan menyimpan logs dari banyak workload.
Alur logging dasar di Kubernetes biasanya seperti ini:
Application Container
-> stdout / stderr
-> Node-level Collector atau Agent
-> Central Log Backend
-> Query UI
-> Investigation, Dashboard, AlertTujuannya bukan sekadar menyimpan teks. Tujuannya adalah membuat logs mudah dicari, mudah dipahami, dan tersambung dengan workflow observability lain.
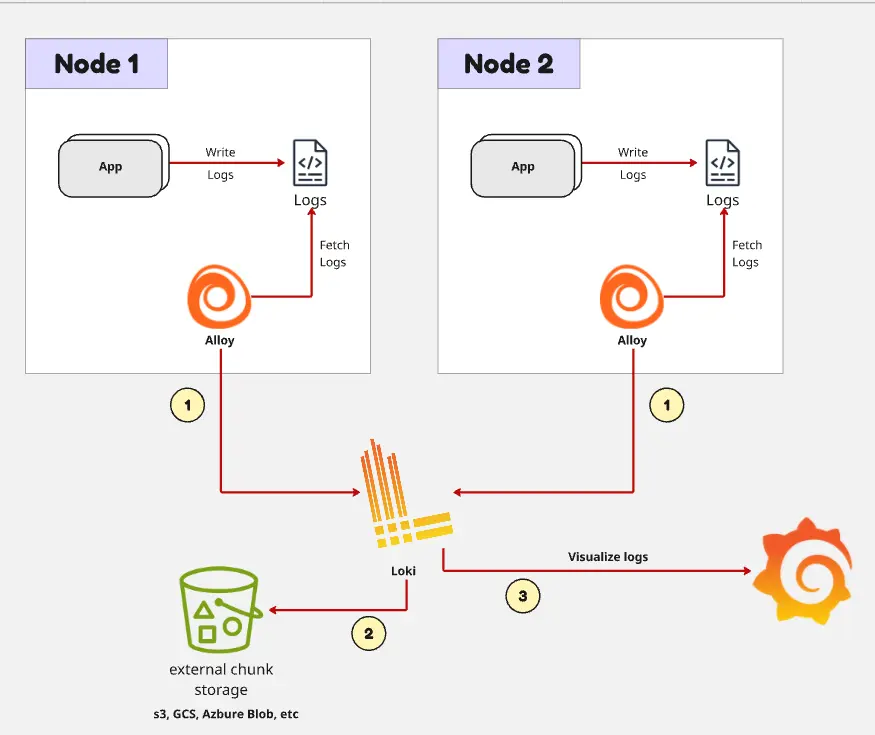
Apa Itu Loki?
Loki adalah log aggregation backend yang umum dipakai bersama Grafana. Loki dirancang di sekitar labels dan log streams, bukan full indexing untuk setiap kata di setiap log line.
Desain ini penting.
Di banyak logging system, setiap pesan log diindeks secara berat supaya pengguna bisa mencari teks apa pun dengan cepat. Loki mengambil pendekatan berbeda: metadata labels diindeks, sementara log chunks disimpan dalam bentuk terkompresi. Query biasanya dimulai dengan memilih labels seperti app, namespace, cluster, atau environment, lalu memfilter log lines di dalam stream yang terpilih.
Loki stream adalah kumpulan log entries dengan label set yang sama. Contohnya:
Labels:
cluster="prod"
namespace="payments"
app="payment-api"
container="api"
Log Stream:
2026-05-24T10:15:01Z level=info message="payment request received"
2026-05-24T10:15:02Z level=error message="provider timeout"
2026-05-24T10:15:03Z level=info message="request finished"Karena itu, label design menjadi salah satu bagian paling penting saat mengoperasikan Loki. Labels yang baik membantu mempersempit ruang pencarian. Labels yang buruk membuat terlalu banyak stream unik, menaikkan biaya, dan membuat sistem lebih sulit dioperasikan.
Loki bekerja baik ketika logs sudah cukup terstruktur dan platform punya strategi label yang jelas. Di Kubernetes, labels yang umum biasanya berasal dari metadata namespace, pod, container, app, cluster, dan environment.
Apa Itu Grafana?
Grafana adalah layer eksplorasi dan visualisasi yang sering dipakai engineer bersama Loki. Grafana memberi tim cara untuk melakukan query logs, membuat dashboards, membuat alerts, dan berpindah antar observability signals.
Dengan Loki sebagai data source, Grafana bisa dipakai untuk:
- Mencari logs berdasarkan labels dan time range.
- Memfilter log lines memakai LogQL.
- Membuat dashboards untuk volume logs, pola error, atau event spesifik service.
- Membuat alerts dari log queries.
- Mengorelasikan logs dengan metrics dan traces.
Workflow korelasi adalah bagian yang membuat Grafana sangat berguna. Engineer bisa mulai dari dashboard yang menunjukkan latency naik, lompat ke traces untuk request yang lambat, lalu melihat logs dari service dan rentang waktu yang relevan.
Metric Alert
-> Grafana Dashboard
-> Trace untuk Request Lambat
-> Related Service Labels
-> Loki Log Query
-> Konteks Error dari AplikasiAlur ini mengurangi waktu yang terbuang untuk menebak harus melihat ke mana. Daripada membuka banyak terminal dan mencari pod secara acak, engineer mengikuti bukti dari satu signal ke signal lain.
Apa Itu Logstash?
Logstash adalah data processing pipeline yang bisa menerima events, melakukan parsing dan transformasi, memperkaya data, memfilter event, lalu mengirimkannya ke satu atau beberapa tujuan.
Logstash lebih tradisional diasosiasikan dengan pipeline ELK atau Elastic-style, di mana logs mengalir lewat Logstash menuju Elasticsearch lalu dieksplorasi di Kibana. Logstash bukan komponen wajib untuk Loki, dan banyak deployment Loki berjalan sangat baik tanpa Logstash.
Perbedaan ini penting.
Untuk pipeline logging Kubernetes yang lebih sederhana, tim sering memakai collector atau shipper yang mengirim container logs langsung ke Loki. Ini bisa cukup ketika logs sudah terstruktur, labels bersih, dan platform tidak membutuhkan transformasi berat.
Logstash menjadi lebih berguna saat environment lebih berantakan:
- Logs datang dari banyak format dan sistem legacy.
- Tim membutuhkan parsing kompleks sebelum storage.
- Field sensitif harus dihapus atau dimasking.
- Events perlu enrichment dari data eksternal.
- Logs harus dirouting ke beberapa tujuan.
- Tim berbeda membutuhkan format output yang berbeda.
Dengan kata lain, Logstash sebaiknya diperlakukan sebagai layer pemrosesan opsional, bukan sesuatu yang wajib ada di setiap pipeline Loki.
Bagaimana Semuanya Terhubung
Pipeline logging sederhana dengan Loki dan Grafana bisa sangat langsung:
Application Logs
-> Collector / Shipper
-> Loki
-> Grafana
-> Search, Explore, Dashboard, AlertDi Kubernetes, collector biasanya berjalan dekat dengan workload, seringnya sebagai DaemonSet di setiap node. Collector membaca container logs, menambahkan metadata Kubernetes sebagai labels, lalu mengirim logs ke Loki.
Saat Logstash ditambahkan, biasanya ia berada di jalur pemrosesan sebelum backend akhir:
Application Logs
-> Collector / Shipper
-> Logstash
-> Parse
-> Enrich
-> Filter
-> Route
-> Loki atau Log Destination Lain
-> GrafanaIni bisa berguna, tetapi juga menambah biaya operasional. Logstash membutuhkan compute resources, konfigurasi, scaling, monitoring, dan failure handling. Pipeline dengan Logstash bisa lebih kuat, tetapi tidak otomatis lebih baik.
Keputusan praktisnya seperti ini:
- Jika logs sudah terstruktur dan hanya membutuhkan metadata labels, jaga pipeline tetap sederhana.
- Jika logs membutuhkan transformasi serius sebelum storage atau routing, pertimbangkan Logstash.
Konsep Inti
Konsep pertama adalah structured logging.
Structured logs lebih mudah diparse, diquery, dan dikorelasikan dibanding teks bebas. Backend service sebaiknya memakai field yang konsisten seperti level, message, service, trace_id, span_id, request_path, status_code, dan duration_ms.
Contohnya:
Structured log yang baik:
level=error service=payment-api trace_id=abc123 status_code=502 message="payment provider timeout"
Lebih sulit diquery:
Payment failed again, provider seems slow, maybe timeout for request abc123Konsep kedua adalah label design.
Labels sebaiknya menjelaskan dimensi stabil yang membantu engineer mempersempit pencarian logs. Labels yang baik biasanya punya jumlah kemungkinan nilai yang terbatas. Labels yang buruk punya terlalu banyak nilai unik dan menciptakan high cardinality.
Labels yang Baik
-> cluster="prod"
-> namespace="payments"
-> app="payment-api"
-> environment="production"
-> container="api"
Labels yang Buruk
-> request_id="req-9f7a2c1e..."
-> user_id="user-839102..."
-> session_id="sess-774992..."
-> order_id="ord-20260524-000912..."
-> email="[email protected]"
-> timestamp="2026-05-24T10:15:01.923Z"request_id, user_id, session_id, order_id, email, timestamp, dan field lain yang sangat unik biasanya adalah label yang buruk. Nilai-nilai itu tetap berguna di log body atau structured metadata, tetapi sebaiknya tidak dijadikan Loki labels kecuali ada alasan yang sangat jelas dan biaya operasionalnya dipahami.
Konsep ketiga adalah query workflow.
Di Loki, pola query yang umum adalah mulai dari labels yang luas, lalu mempersempit dengan filter teks atau filter structured. Misalnya, engineer bisa memilih logs untuk app="payment-api" di namespace payments, lalu memfilter level="error" atau pesan error spesifik dari provider.
Konsep keempat adalah retention.
Tidak semua logs perlu disimpan selamanya. Debug logs mungkin hanya berguna dalam window pendek. Audit logs atau security-related logs mungkin perlu retention lebih lama. Event terkait payment atau compliance bisa punya kebutuhan terpisah. Retention harus disengaja, terdokumentasi, dan selaras dengan biaya.
Contoh Praktis
Bayangkan tim platform menerima alert: kegagalan checkout meningkat di production.
Dashboard metrics menunjukkan spike response 5xx dari payment service. Traces menunjukkan request lambat di sekitar call ke payment provider. Sekarang engineer perlu tahu apa yang dilaporkan aplikasi saat kegagalan itu terjadi.
Alur investigasi praktis bisa seperti ini:
Payment Error Rate Alert
-> Buka Grafana Dashboard
-> Konfirmasi spike untuk payment-api
-> Inspect traces untuk checkout request yang lambat
-> Copy trace_id atau persempit time window
-> Query Loki logs untuk payment-api
-> Temukan provider timeout dan retry behavior
-> Putuskan rollback, config fix, atau eskalasi ke providerDi Grafana Explore, engineer mungkin melakukan query logs untuk payment API di production:
{cluster="prod", namespace="payments", app="payment-api"}
|= "provider timeout"Jika aplikasi mengeluarkan structured logs dan menyertakan trace IDs di log body, engineer bisa mengorelasikan trace yang gagal dengan log lines yang tepat dari request yang sama.
Investigasi menjadi lebih kuat ketika logs membawa konteks operasional:
- Provider mana yang dipanggil.
- Endpoint mana yang gagal.
- Apakah request diretry.
- Apakah kegagalan berupa timeout, validation error, authentication error, atau rate limit.
- Versi deployment mana yang sedang berjalan.
Bagian pentingnya bukan hanya memiliki logs. Bagian pentingnya adalah memiliki logs yang membantu menjawab pertanyaan operasional berikutnya.
Kapan Logstash Benar-benar Layak Dipakai
Logstash layak dipertimbangkan ketika logging pipeline membutuhkan lebih dari sekadar collection dan shipping.
Misalnya, sebuah platform mendukung beberapa tim:
- Service Go baru mengeluarkan JSON logs.
- Service Java lama mengeluarkan multiline stack traces.
- Integrasi legacy mengeluarkan custom text logs.
- Security requirement meminta field tertentu dimasking.
- Sebagian logs harus masuk ke Loki untuk investigasi engineering.
- Logs lain juga harus dikirim ke long-term archive storage.
Di environment seperti itu, layer pemrosesan bisa membantu menormalisasi kondisi yang berantakan.
Logstash bisa memparse format berbeda, mengekstrak fields, memperkaya events, menghapus data sensitif, dan merouting logs ke beberapa tujuan. Ini berguna ketika platform membutuhkan bentuk log yang konsisten dari sumber yang tidak konsisten.
Tetapi Logstash harus benar-benar punya alasan untuk ada di arsitektur. Jika pipeline saat ini adalah:
Application JSON Logs
-> Kubernetes Metadata
-> Loki
-> Grafanadan engineer sudah bisa melakukan query logs dengan efektif, menambahkan Logstash mungkin hanya menambah satu komponen operasional lagi.
Default yang lebih baik adalah mulai sederhana, memperbaiki struktur logs dari aplikasi, mendefinisikan labels yang baik, lalu menambahkan processing hanya ketika kebutuhan operasionalnya jelas.
Hal yang Perlu Diwaspadai
Hal pertama adalah high-cardinality labels. Loki sangat bergantung pada disiplin label. Labels seperti request ID, user ID, session ID, transaction ID, email, timestamp yang sangat spesifik, dan IP address unik bisa menciptakan terlalu banyak stream. Simpan nilai-nilai itu di log body atau structured metadata, bukan sebagai Loki labels.
Hal kedua adalah logs yang tidak terstruktur. Jika setiap tim memakai format log yang berbeda, pencarian menjadi melelahkan dan parsing menjadi rapuh. Tim sebaiknya menyepakati sekumpulan kecil field umum untuk production services.
Hal ketiga adalah biaya retention. Logs bisa tumbuh sangat cepat. Debug-level logs dari service yang sibuk bisa menjadi mahal dan noisy. Tentukan logs mana yang layak disimpan, pada level apa, dan selama berapa lama.
Hal keempat adalah over-processing. Pipeline Logstash yang kompleks bisa menjadi production system tersendiri. Ia butuh version control, testing, rollout strategy, monitoring, dan ownership. Jika hasil yang sama bisa dicapai dengan structured application logs dan jalur collector yang lebih sederhana, pilih jalur yang lebih sederhana.
Hal kelima adalah korelasi yang buruk. Logs jauh lebih berguna ketika menyertakan trace IDs atau field korelasi lain. Jika metrics, traces, dan logs tidak bisa dihubungkan saat incident, engineer akan kehilangan waktu berpindah antar tool secara manual.
Penutup
Loki dan Grafana membentuk stack centralized logging yang praktis untuk Kubernetes dan sistem cloud-native. Loki menyimpan dan melakukan query logs berdasarkan labels dan streams, sementara Grafana memberi engineer tempat yang familiar untuk mengeksplorasi logs bersama metrics dan traces.
Logstash bisa berguna, tetapi sifatnya opsional. Ia paling cocok ketika logs membutuhkan parsing, enrichment, filtering, atau routing yang serius sebelum sampai ke backend. Banyak tim bisa menjalankan pipeline yang lebih sederhana tanpa Logstash dan tetap mendapatkan nilai operasional yang sangat baik.
Pelajaran utamanya adalah memperlakukan logging sebagai bagian dari sistem observability, bukan sekadar tempat membuang teks. Gunakan structured logs. Pilih labels yang stabil. Hindari high-cardinality fields. Buat retention secara sengaja. Permudah perpindahan dari metrics ke traces ke logs saat production memberi pertanyaan yang sulit.
Dalam konteks platform engineering, centralized logging bukan hanya tentang mencari pesan lama. Ia membantu engineer memahami apa yang sedang dilakukan sistem pada momen yang penting.